EMNLP 2022
논문 링크: https://arxiv.org/pdf/2202.12837.pdf
요약
모델은 프롬프트로 주어지는 ground truth input-label 쌍에 크게 영향을 받지 않고 task를 수행한다.
하지만 input-label 형식은 맞든 틀리든 간에 주어져야 한다.
Introduction
우리는 ground truch demonstration이 in-context learning에 꼭 필요하지 않는다는 것을 보인다. 그 대신 label space와 input text가 어떤 형태로든 주어져야 한다.
Related work
최근 in-context learning의 불안정성에 대한 연구가 이루어졌다. ([1, 2, 3]). [4]는 in-context learning이 latent concept을 추론하기 위해 demonstration을 이용한다는 것에 대한 이론적인 분석을 Bayesian inference로 formalize 하여 알아냈다.
Experimental Setup
실험은 6가지 모델에 대해 이루어졌으며, 각 모델들은 direct, channel method을 이용해 실험했다(이 부분은 [5] 참고). 그리고 GLUE, SuperGLUE 등의 dataset을 이용하여 classification, multi-choice task들에 대해 평가했다. Example의 개수는 기본적으로 16을 사용했다.
Ground Truth Matters Little
Demonstration이 없을 때, input example과 라벨이 주어졌을 때, input example에 대해 random label이 주어졌을 때를 비교해봤다.

정답 label을 줬을 때는 demonstration이 없을 때와 비교해서 좋은 성능을 보여주었지만 random label을 주었을 때와 크게 성능 차이가 나지 않았다. 이는 모델이 input-label 연관성을 주어진 demonstration을 이용하지 않고도 찾아낼 수 있음을 의미한다.
또한 틀린 label을 준 경우에도 상당히 좋은 성능을 보여주었다.

Example의 개수인 k에 대해서는 8 이상이 되면 성능이 증가하지 않고 줄어들었다. 이는 example의 개수가 늘어날 수록 좋은 결과를 보이는 supervised training과는 다른 결과이다. 우리는 example input이나 label 등이 작은 양의 data로부터 추론 가능한 것으로 추측한다.
Why does In-context Learning Work?
이제 input-label이 아닌 다른 요소들이 성능에 어떤 영향을 미치는 지 알아본다.
Distribution of the input
Input으로 external corpus로부터 문장을 sample하여 실험해봤다. 이 때는 성능이 많이 떨어졌다.

이를 통해 in-distribution input이 중요하다는 점을 알 수 있다. 이는 in-distribution text가 task를 language modeling과 연관지을 수 있기 때문이라고 생각된다. 그리고 language modeling은 항상 in-distribution text에 대한 예측을 통해 학습한다.
Impact of the label space
원래의 task에 사용되던 label을 random한 다른 단어로 바꾸어 실험했다. 이 경우 상당히 성능이 낮아졌다.
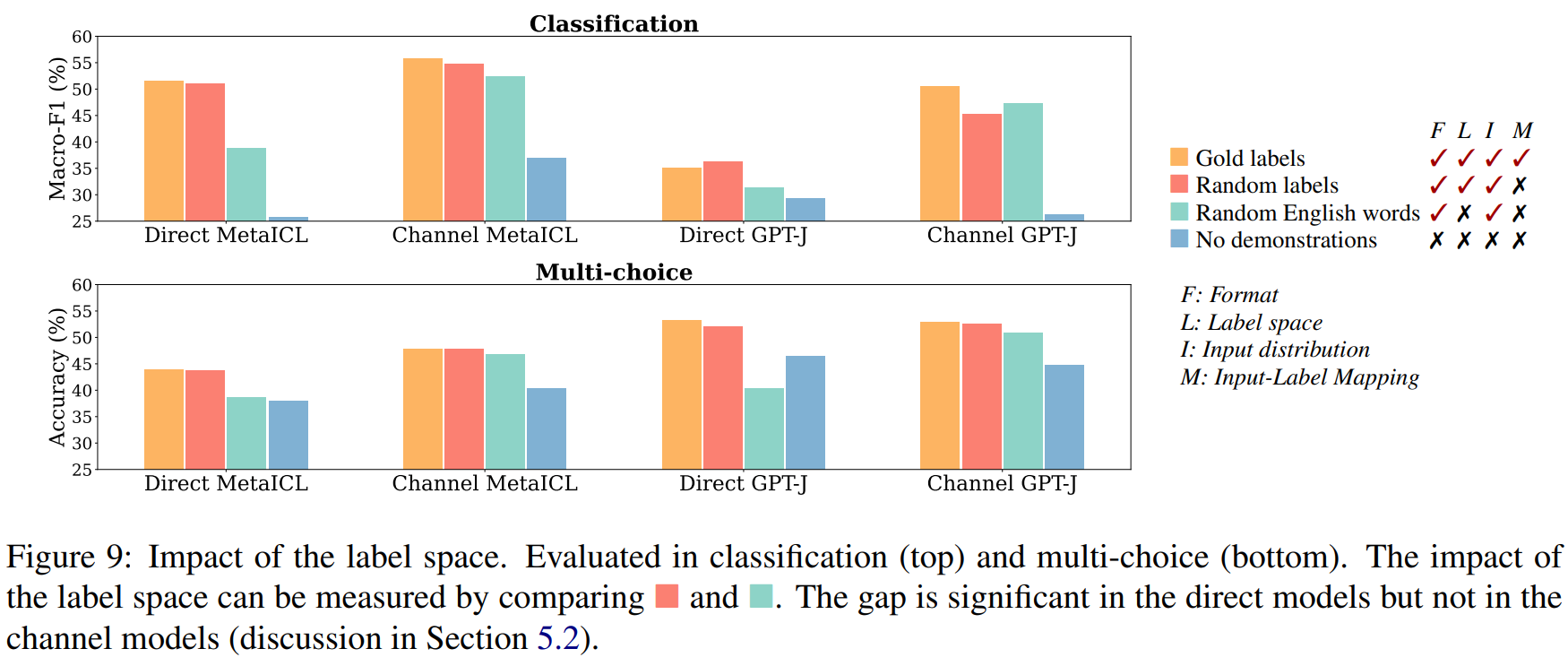
Impact of input-label paring
Label을 주지 않은 경우, label만 준 경우 두가지를 실험해봤다. 이 경우 성능이 demonstration을 안 준만큼 나빠졌다(진한 보라색, 친한 초록색).
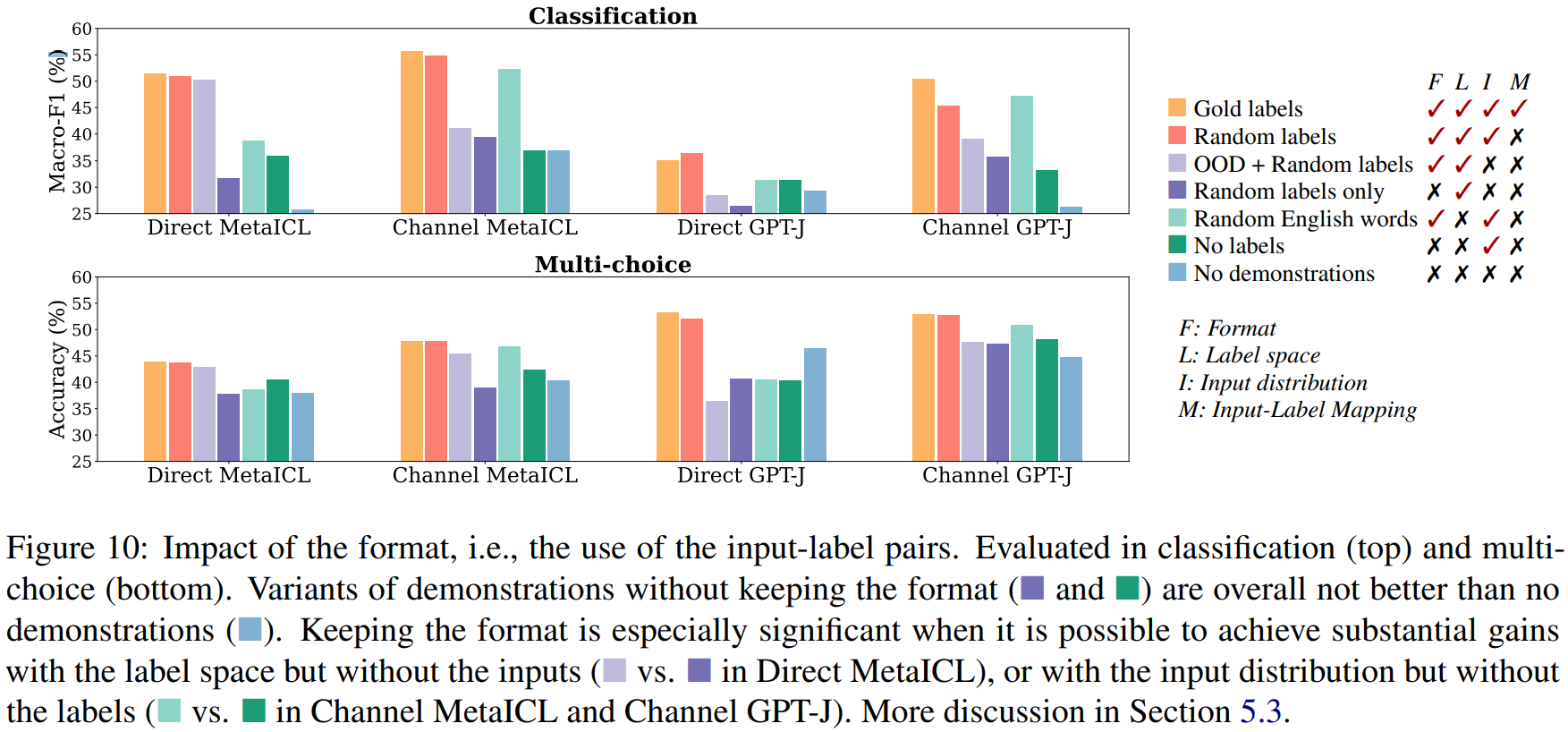
이는 모델이 input-label pair를 보고 text input이 들어왔을 때 같은 관계를 추론하여 답을 낸다는 것을 알게 해준다. 또한 corpus 내의 random한 문장과 정답 라벨을 사용한 경우, input과 random label을 준 경우(연한 보라색, 연한 청록색) 상당히 좋은 성능 변화를 보인다는 점도 재밌는 점이다. 이를 통해 format 자체(input-label)를 유지하는 것이 중요하다는 점을 알 수 있다.
Discussion & Conclusion
Demonstration에는 input-label 쌍이 어떤 식으로든 꼭 필요하다.
과연 모델이 test 시에 학습을 하는가에 대해 생각해보면, 학습을 training data에 대해서는 하지 않는다. Input-label의 정답 여부는 중요하지 않는 것을 봐서 어떤 task를 배우는 게 아니라 pretraining 시 학습했던 prior를 이용한다고 볼 수 있다. 하지만 좀 더 범위를 넓혀서 주어진 input에 맞춰 좀 더 정확한 예측을 한다는 측면에서는 학습을 한다고 불 수도 있다.
[6]도 demonstration은 task location을 위해 존재하며, task를 수행하기 위한 능력은 pretraining 시에 학습한다고 주장한다. Pretrained model의 zero shot 성능이 좋지는 않더라도, pretrained model이 task를 수행할 수 있는 능력이 있음을 제안한다. 반면 이를 통해 pretraining 시에 학습하지 못했던 task들은 in-context를 통해서도 잘 수행하지 못한다는 것을 암시한다. 이런 사실들을 통해 pretrained modeld의 능력을 더 잘 발휘시키고, 다양한 종류의 task에 대한 수행능력을 학습시킬 수있는 방법을 연구할 수 있을 것이다.
우리는 instruction을 통해 language model이 갖고 있는 능력을 발휘시킬 수는 있지만 새로운 task에 대한 수행능력을 부여한다고 보지는 않는다. 이는 irrelevant, misleading instruction이 성능에 큰 영향을 미치 않는다는 연구 결과[7]를 통해서도 알 수 있다.
이 실험을 통해 단순히 input과 label(아무 input, 아무 label)을 demonstration을 주어 성능을 향상시킬 수 있음을 보였고, 이는 모델의 zero-shot baseline level이 우리가 생각했던 것보다 상당히 높음을 의미한다.
결론
상당히 쉽게 읽히는 논문이었고, 재미있는 결과를 보여주었다.
이전에 읽었던 [7]과 비슷한 느낌의 논문이다.
우리가 모델에 원하는 것이 대략적으로 어떤 것인가를 단순히 training input, label로 주는 것이 아니라 demonstration 내에 example로써 주는 것이 많은 도움이 된다.
반대로 말하면 이게 모델이 필요로 하는 것이며, 갖고 있지 못한 능력이라고도 볼 수 있다.
Reference
[1] Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2021. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. arXiv preprint arXiv:2104.08786.
[2] Tony Z Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In ICML.
[3] Swaroop Mishra, Daniel Khashabi, Chitta Baral, Yejin Choi, and Hannaneh Hajishirzi. 2021a. Reframing instructional prompts to gptk’s language. arXiv preprint arXiv:2109.07830.
[4] Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. 2022. An explanation of in-context learning as implicit bayesian inference. In ICLR.
[5] Sewon Min, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2021a. Noisy channel language model prompting for few-shot text classification. arXiv preprint arXiv:2108.04106
[6] Laria Reynolds and Kyle McDonell. 2021. Prompt programming for large language models: Beyond the few-shot paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems.
[7] Albert Webson and Ellie Pavlick. 2022. Do promp-based models really understand the meaning of their prompts? In NAACL-HLT
'NLP > Prompt tuning' 카테고리의 다른 글
| Towards a Unified View of Parameter-Efficient Transfer Learning 논문 리뷰 (0) | 2023.01.05 |
|---|---|
| Can language models learn from explanations in context? 간단 리뷰 (0) | 2022.12.12 |
| Do prompt-based models really understand the meaning of their prompts? (0) | 2022.12.09 |
| AutoPrompt 논문 리뷰 (0) | 2022.12.06 |



