2022 NAACL
논문 링크: https://arxiv.org/abs/2109.01247
요약:
Prompt와 target word들이 Language Model의 성능에 어떤 영향을 끼치는지 알아보는 논문이다.
Language Model의 Prompt와 Target word들을 바꿔가면서 NLI task의 성능이 zero-shot, few-shot에서 어떻게 변화하는지 실험해봤다.
Prompt(Instruction)이 어떤 내용을 갖고 있는가는 생각보다 큰 영향을 미치지 않았고, 오히려 target word들의 형태가 큰 영향을 미쳤다.
실험을 잘 했고, 재밌는 결과들을 보여줬으며 해석이 약간 억지스러운 면이 있긴 하지만 많은 것을 생각해보게 만드는 논문이다.
Abstract
Task instruction 역할을 할 것으로 기대하는 prompt를 추가해서 학습을 빠르게 할 수 있을 것이라 생각하지만 task와 전혀 상관없는 내용의 prompt를 넣어줘도 학습에 도움이 되는 경우도 있다. 이렇게 사람처럼 task instruction을 이해하는 모델이 얼마만큼 성능을 향상시킬 수 있을 지 알아본다.
Introduction
Prompt를 추가하여 기존의 fine-tuned 모델의 zero-shot, few-shot 성능을 높일 수 있었다. 이에 따라 prompt는 사람이 instruction을 보는 것처럼 모델의 학습을 빠르게 해주는 의미있는 안내문이라는 가설에 힘을 실어줬다. 하지만 어떤 연구에서는 학습을 통해 얻은 prompt보다 전문가가 쓴 prompt가 더 유용하다는 결과가 있음을 보였다.
이 논문에서는 실험을 통해 어떤 prompt가 가장 학습에 도움이 되는지를 알아보며, 상관없거나 잘못된 prompt도 학습에 도움을 준다는 사실을 보인다. 그리고 prompt에 대해 robust하다는 것은 반대로 말해 prompt에 영향을 덜 받는다는 것으로도 여겨질 수 있다. Language model은 오히려 prompt instruction보다 target word에 더 민감하다.
Related Work
Prompt-based models
Continuous prompt가 task-specific한 instruction인지 아니면 단순히 보다 효과적인 model parameter인지는 명확하지 않다. [1]
Analyses of Prompts
우리의 실험 결과가, 모델이 정교한 instruction들의 도움을 받을 수 있다고 밝힌 [2]의 결과와 반대되는 결과일 수도 있다. 하지만 그들은 instruction을 priming을 포함할만큼 광범위하게 정의한다. 그리고 GPT-3가 positive examples에서 가장 크게 도움을 받고, definition을 통해서는 mild한 도움을 받으며, negative example은 성능을 악화시킨다. 따라서 그들의 instruction에 대한 정의에서 priming instruction, narrow instruction들을 제외시킨다면 instruction의 효과가 크지 않다는 우리의 결과와 비슷해진다. 또, [3]는 priming example들은 효과적이지만 instruction들은 모델의 성능에 크게 상관없다고 밝힌다. [4]는 모델이 input text와 label 간의 관계를 학습하는 데 도움을 준다고 한다.
Effect of Templates
Method
5가지 종류의 template을 만들어 실험했다.
1. Instructive: NLI를 처음 본 사람이 설명한 NLI task
2. Misleading-Moderate: 약간 부정확한 NLI task 설명
3. Misleading-Extreme: 많이 부정확한 NLI task 설명
4. Irrelevant: Premise - NLP task와 상관없는 문구들 - hypothesis 로 이루어진 input
5. Null: 추가 text 없이 Premis - Hypothesis만 사용
예시

Results
Irrelevant template을 사용한 T5 3B모델은 instructive template을 사용할 때만큼 빠르게 학습했다.

이 결과를 봤을 때, instructive template의 영향력이 그리 크지 않다, 모델이 prompt를 무시하고 PLM의 능력 만으로 학습을 한 것이 아닌가 생각된다.
Instructive template은 두 개의 misleading template보다는 확실히 성능이 좋았다. Null template 성능은 제일 낮았다.
Zero-shot 상황에서의 실험 결과는 다음과 같다. T0 3B모델에서는 instructive template과 다른 모든 template들 간의 성능 차이가 크지 않았다. T0 11B 모델에서는 instructive template과 misleading moderate template 간의 차이만 크지 않았다(라고 하는데 이정도면 의미있는 차이라고 보이는데... 아마 뒤에 나오는 target word들이 미치는 영향보다는 작다는 의미인 것 같다). T0++모델에서만 instuctive template이 유의미한 효과를 냈다.

Discussion
Prompt를 생성할 때 전문가의 도움을 받아 명확하고 정확하게 task의 설명을 써야할 것 같지만 zero-shot 상황에서의 T0++를 제외한 다른 모델에서는 부적잘한 template을 사용했을 때의 성능이 적절한 prompt를 사용했을 때와 비슷한 경우들이 나타났다. 그리고 GPT-3에서도 이런 현상이 나타난 것을 보면 scaling의 문제는 아닌 것 같다. T0모델은 instruction tuning을 이용해 성능을 향상시키고 robust한 모델을 만들었으나 그만큼 prompt의 종류에 구애받지 않는 성능을 보여주었다. (T0++라면 이해가 가지만 T0는 차이가 있어 보이는데...)

Zero-shot 세팅에서 T0++가 prompt의 종류에 따라 다른 성능을 보인 것은 긍정적인 결과이지만, 여전히 instructive template과 비슷한 성능을 내는 template들이 존재한다. 또한 prompt가 적절하더라도 모델의 성능이 72%인 것을 보면 모델이 instruction을 따른다고 보기도 힘들다.
Effect of Target Words
Method
Target word가 바뀔 때 성능에 어떤 영향을 미치는지 알아본다.
1. Yes-no: 모델이 entailment일 때는 yes를, non-entailment일 때는 no를 예측한다.
2. Yes-no-like: 의미적으로 yes-no와 비슷한 단어들 - true/false, positive/negative - 을 예측한다.
3. Arbitrary: 모델이 임의의 단어를 예측한다. 예: entailment - cat, non-entailment - dog
4. Reversed: 모델이 반대 단어를 예측한다. entailment - no, non-entailment - yes
Result
Albert, T0 모두 yes-no target일 때 가장 빨랐고, yes-no-like target일 때가 그다음이었으며 다른 두 개의 target일 때와 차이가 많이 났다.
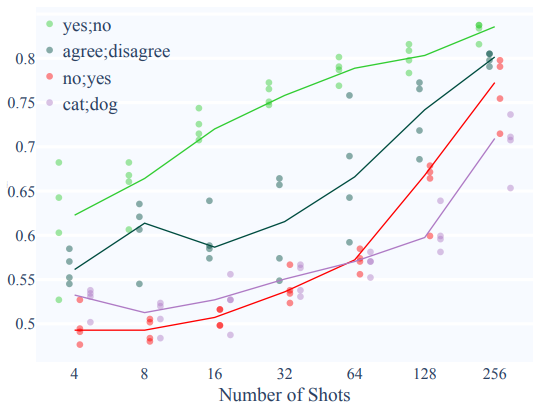
32-shot 상황에서 yes/no와 no/yes의 차이는 template 종류에 의한 차이보다 훨씬 컸다. Template 종류와, target words 종류를 변화하면서 실험한 결과는 아래와 같다.
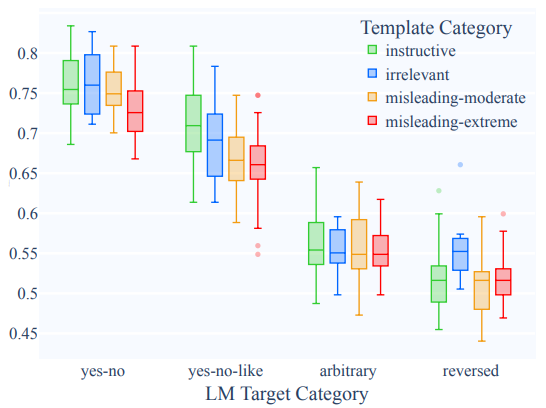
Discussion
모델이 arvitrary, reversed target words에 대해 안좋은 성능을 보인다는 것은 긍정적인 결과이다. 하지만 이 실험에서도 부정적인 면이 남아있다. 첫번째로 target words의 영향이 prompt보다 더 크다는 것이다.

위의 두가지 input에 대해 실험한 결과는 아래와 같다 - 1의 결과가 2보다 훨씬 좋다.
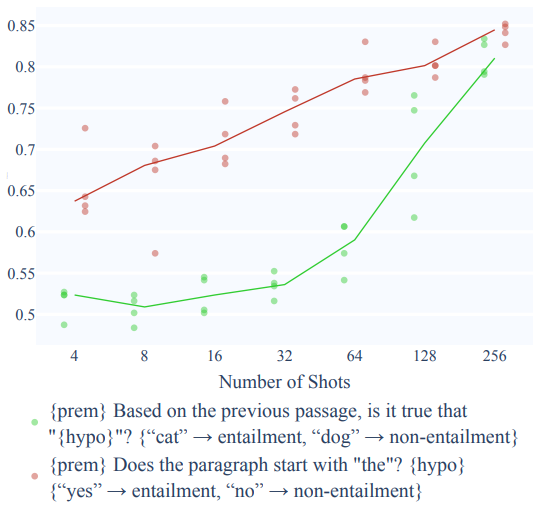
물론 2의 task를 수행하기 위해선 사람도 few shot learning을 해야할 것이다.
그리고 yes-no-like target들도 yes-no target보다 천천히, 나쁘게 학습된다. Prompt에 "True or false?"와 같은 힌트 문구들을 추가하는 것도 도움이 되지 않고 오히려 성능을 악화시키는 경우도 생겼다[5, 6].
General Discussion
Summary and Interpretation
Language model이 이상적인 환경에서 좋은 성능을 냈다고 해서 language understanding을 잘한다는 뜻은 아니다[7, 8, 9, 10]. 왜냐하면 부적절한 input일 때도 좋은 성능을 내기 때문이다. Input이 좋지 않은데도 좋은 예측 결과를 보인다는 것이 모델이 인과가 같은 방식으로 추론하는지에 대한 의문을 제기한다.
Alternative Interpretations and Future Directions
Accuracy로 이해 능력을 직접적으로 측정할 수 있지는 않다. Instruction은 완벽히 이해했지만 task 자체가 너무 여려운 경우(lack of competence)도 있고, instruction을 무시한 경우도 있다(lack of compliance). 이 두가지 경우를 고려해본다.
Lack of competence
Zero shot 상황에서는 모델이 NLI instruction을 이해 못했는지, 아니면 NLI 자체를 수행할 능력이 없는 것인지 확실치 않다. 하지만 모델이 학습을 통해 높은 정확도를 보이는 few-shot 상황에서는 lack of competence를 생각하지 않아도 된다.
다른 반론은 아마도 그 어떤 모델도 실제로 premis가 hypothesis를 entail하는지를 판단하지 못한다는 것이다. 단순히 피상적인거나 heuristic한 feature들만 이용할 수도 있다. 만약 진짜로 entailment에 대해 추론할 수 있어야 NLI instruction이 영향을 미치게 된다는 주장이 있다.
Lack of compliance
다른 해석으로 model이 prompt를 무시해서 template 종류에 따른 성능 변화가 크지 않다는 것이 있을 수 있다. 하지만 이럴 경우 model의 성능 변화가 훨씬 적어야 한다.
다른 반론으로 모델이 instruction의 syntactic, semantic 특징들보다 피상적이고 heuristic한 feature들만 사용한다는 것이 있다[11, 12].
References
[1] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor BergKirkpatrick, and Graham Neubig. 2021. Towards a unified view of parameter-efficient transfer learning.
[2] Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. 2021. Natural instructions: Benchmarking generalization to new tasks from natural language instructions.
[3] Andrew K Lampinen, Ishita Dasgupta, Stephanie CY Chan, Kory Matthewson, Michael Henry Tessler, Antonia Creswell, James L McClelland, Jane X Wang, and Felix Hill. 2022. Can language models learn from explanations in context?
[4] Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work?
[5] Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, ... Thomas Wolf, and Alexander M. Rush. 2021. Multitask prompted training enables zero-shot task generalization.
[6] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners
[7] Koustuv Sinha, Prasanna Parthasarathi, Joelle Pineau, and Adina Williams. 2021. UnNatural Language Inference. ACL
[8] Joe O’Connor and Jacob Andreas. 2021. What context features can transformer language models use? arXiv preprint arXiv:2106.08367
[9] Thang Pham, Trung Bui, Long Mai, and Anh Nguyen. 2021. Out of order: How important is the sequential order of words in a sentence in natural language understanding tasks? In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021
[10] Ashim Gupta, Giorgi Kvernadze, and Vivek Srikumar. 2021. Bert & family eat word salad: Experiments with text understanding
[11] Charles Lovering, Rohan Jha, Tal Linzen, and Ellie Pavlick. 2021. Predicting inductive biases of pretrained models. ICLR
[12] Alex Warstadt, Yian Zhang, Xiaocheng Li, Haokun Liu, and Samuel R. Bowman. 2020. Learning which features matter: RoBERTa acquires a preference for linguistic generalizations (eventually). EMNLP
'NLP > Prompt tuning' 카테고리의 다른 글
| Towards a Unified View of Parameter-Efficient Transfer Learning 논문 리뷰 (0) | 2023.01.05 |
|---|---|
| Rethinking the Role of Demonstrations:What Makes In-Context LearningWork? 간단 리뷰 (0) | 2022.12.13 |
| Can language models learn from explanations in context? 간단 리뷰 (0) | 2022.12.12 |
| AutoPrompt 논문 리뷰 (0) | 2022.12.06 |



